Progressive Distillation for Fast Sampling of Diffusion Models
marii
A Quick Overview
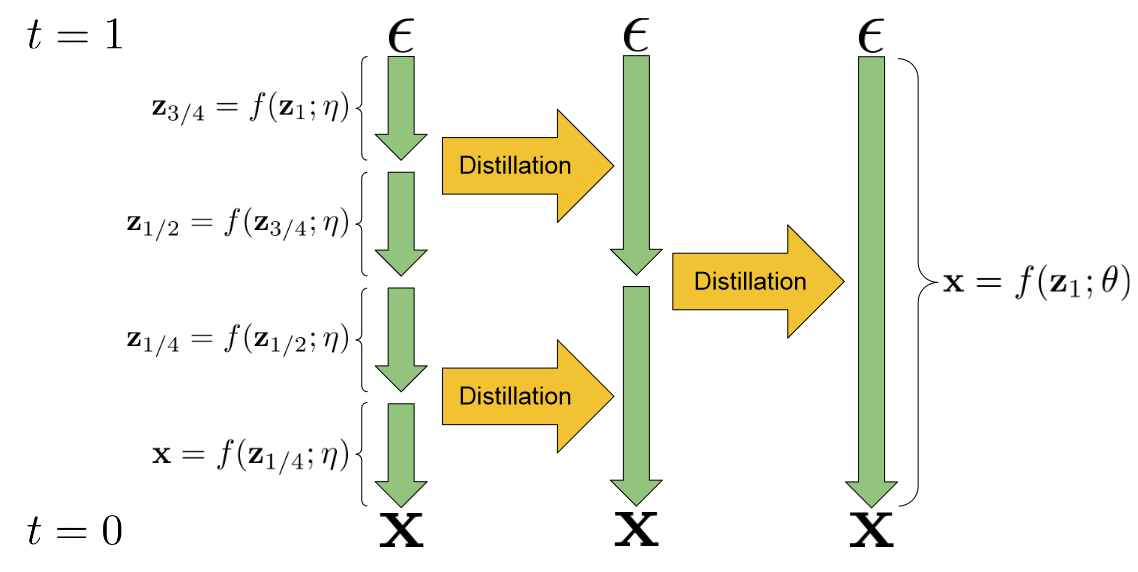
progressive_distillation.png
\(\tilde x\) is our target
We take two steps of DDIM
Then \(\tilde x\) is the image associated with taking two steps.
The target of our distilled model is the output of our original diffusion model taking two ddim steps.
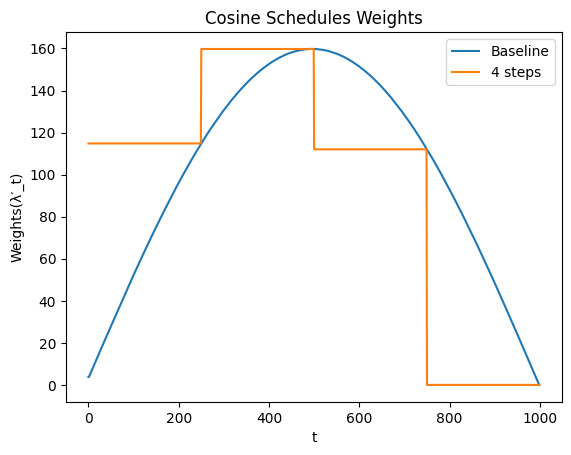
We will cover \(w()\) later
progressize_algorithm.png
Questions so far?
Why is \(\tilde x\) our target, and not \(\epsilon\)?
Break down of relationship between x and \(\epsilon\)
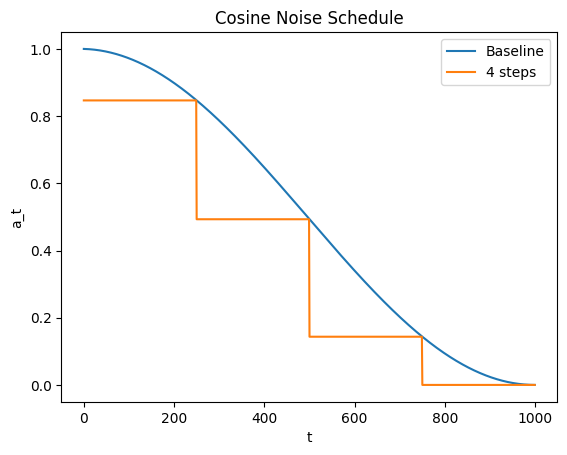
In the case of a single timestep \(||\epsilon_\theta(x_T)-\epsilon||^2_2\), could be optimized by an identity, and is not particularly useful. As our number of steps decreases to 4, this step becomes 1/4 of our total steps. (\(a_T\simeq0\))
\(w()\) is 0, or very close to 0 near 0 and T. This problem becomes more aparent when we decrease the number of steps to 4. Our weights \(w\) becomes almost 0 for one of our 4 steps!
“We sample this discrete time such that the highest time index corresponds to a signal-to- noise ratio of zero, i.e. α1 = 0, which exactly matches the distribution of input noise z1 ∼ N (0, I) that is used at test time”
This is critical, I lost a lot of time on this one. I didn’t notice the problem until late in the process, so this might have actually been the cause for many other issues.
Cosine schedule seemed important for training model that predicts \(x\) instead of \(\epsilon\). Otherwise training unstable.
I did not succeed in using this technique on a parent model that predicts the noise. This may have been a bug, but training was a lot smoother with a parent that predicted \(x\) instead of \(\epsilon\).